2025年 5月 8日に ipullrank で公開された Francine Monahanという方の「An Introduction to Relevance Engineering: The Future of Search」を読みました。
アイオイクスさんの翻訳記事も読みました。
https://seojapan.com/column/column-14753
上記内容を自分なりに整理し、AIとも競技を重ねた結果、とある試みをトライしました。
それは、
関連性スコアの可視化(高度施策):記事内容と検索クエリの「ベクトル距離」を測る
というアクションです。
「ベクトル」って表現最近SEOに絡ませる人よくいるなぁ〜。
格好良いな〜って感じで…。
目次
具体的なアウトプットイメージ
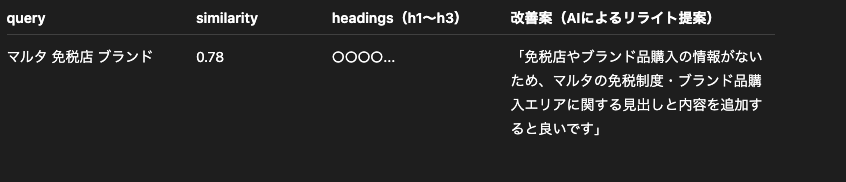
こんな感じ。
類似度スコア(similarity)が1に近いほど高関連性、0以下ならほぼ無関係という考え方みたいです。
タイトルとクエリの関連性だけだと判断材料が弱すぎるので、
・対象URLの見出し構成を(h1〜h3)確認
・その上でAIによる改善案も出す
といった仕組みにしました。
使ってみた結果
「有料のAPI叩いでまで使うもんじゃないかな」なんて感じちゃいました。
特に、私は自分で作業を行うケースが多いため、大量の依頼は投げられませんし、プロンプト組んで普通にGPTに投げる方が調整できて早いしお金も必要以上にかからないなぁという。
あとは抜粋されるクエリも「他のクエリによっては…」みたいなことも気になってしまい、アウトプットの調整が必要だなぁと。
一方で作り込みが甘いだけで、AIによる分析パートの展開をもう少し工夫できれば面白そうにも感じています。
- 任意のクエリ(選ぶもよし、表示回数多い順など決めてもよし)
- 任意のURL
- カニバリも考慮して(似ているもの同士の統合提案とか良いですね。)
とかもカバーできると良さそうですね。
この仕組みが合う方
- 大量の記事の精査を短時間で、行わなければいけない方
- アウトプットの質はともかく、叩きとして記事のクオリティを精査したい方
- こういったテクニカルっぽい要素が求められている方
- 叩きの提案だけ投げて、作業を依頼できる方
この辺りのユーザーさんには刺さるのではないかと感じております。
この仕組みが合わない方
- 自分で丁寧な記事精査を行いたい方
- より実践的に記事の改善を求められている方
この辺は難しいかなと。
実装の手順
詳細はPythonファイルにて解説します。
必要なもの
- 下記Pythonを動かす用意(ライブラリのインストールなど)
- GCPにおけるOAuth 認証の準備
- OpenAIのAPIを使う準備
Pythonファイル
import openai
import pandas as pd
import requests
from bs4 import BeautifulSoup
from datetime import date, timedelta
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from numpy import dot
from numpy.linalg import norm
# --- 1. OAuth 認証 ---
SCOPES = ['https://www.googleapis.com/auth/webmasters.readonly']
flow = InstalledAppFlow.from_client_secrets_file('client_secrets.json', SCOPES)
creds = flow.run_local_server(port=0)
# このファイルと同じフォルダに、GCPでJSON形式で認証キーをダウンロードし、「client_secrets.json」という名前で格納
# --- 2. Search Console API 初期化 ---
service = build('searchconsole', 'v1', credentials=creds)
site_list = service.sites().list().execute()
print("🔗 利用可能なプロパティ:")
urls = []
for site in site_list.get('siteEntry', []):
if site['permissionLevel'] != 'siteUnverifiedUser':
print("-", site['siteUrl'])
urls.append(site['siteUrl'])
# GCPであらかじめ、Search Console APIをONにしておいてください。
# --- 3. 使用するサイトURLを選択 ---
target_site = input("使用するサイトURLを入力してください: ").strip()
# --- 4. クエリ+ページの取得 ---
end_date = date.today()
start_date = end_date - timedelta(days=30)
request = {
'startDate': start_date.isoformat(),
'endDate': end_date.isoformat(),
'dimensions': ['query', 'page'],
'rowLimit': 50 #50クエリ分。1000まで任意の数字を選べる。多いほど時間がかかるので注意
}
response = service.searchanalytics().query(siteUrl=target_site, body=request).execute()
rows = response.get('rows', [])
data = []
for row in rows:
query, page = row['keys']
data.append({'query': query, 'page': page})
df = pd.DataFrame(data).drop_duplicates()
# --- 5. 見出し構成の取得 (h1〜h3) ---
def get_headings(url):
try:
res = requests.get(url, timeout=5)
soup = BeautifulSoup(res.text, 'html.parser')
headings = []
for tag in soup.find_all(['h1', 'h2', 'h3']):
txt = tag.get_text(strip=True)
if txt:
headings.append(f"{tag.name}: {txt}")
return '\n'.join(headings)
except:
return ""
df['headings'] = df['page'].apply(get_headings)
df = df[df['headings'] != ""]
#好みに応じて、h4まで入れても良いかも
# --- 6. OpenAI APIキーの入力 ---
from openai import OpenAI
api_key = ""
while not api_key.startswith("sk-"):
api_key = input("🛡️ OpenAI APIキー(sk-〜)を入力して Enter を押してください: ").strip()
if not api_key.startswith("sk-"):
print("⚠️ 正しい形式のAPIキー(sk-で始まる)を入力してください。")
client = OpenAI(api_key=api_key)
# --- 7. Embedding取得とCos類似度計算 ---
def get_embedding(text, model="text-embedding-ada-002"):
response = client.embeddings.create(input=[text], model=model)
return response.data[0].embedding
def cosine_similarity(v1, v2):
return dot(v1, v2) / (norm(v1) * norm(v2))
results = []
for _, row in df.iterrows():
try:
headings_vec = get_embedding(row['headings'])
query_vec = get_embedding(row['query'])
sim = cosine_similarity(headings_vec, query_vec)
results.append({
"query": row['query'],
"url": row['page'],
"headings": row['headings'],
"similarity": round(sim, 4)
})
except Exception as e:
print("❌ スキップ:", row['query'], "→", str(e))
continue
# --- 8. 類似度の低い記事をAIで分析 ---
result_df = pd.DataFrame(results).sort_values(by="similarity").head(50)
#▲(50)ここはリクエスト数に合わせて
def get_rewrite_suggestion(query, headings):
try:
system_prompt = "あなたはSEOの専門家です。見出し構成と検索クエリから、ユーザーの意図に合う改善案を具体的に提案してください。"
user_prompt = f"【検索クエリ】\n{query}\n\n【見出し構成】\n{headings}"
res = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
)
return res.choices[0].message.content.strip()
except Exception as e:
return f"エラー: {e}"
result_df["rewrite_suggestion"] = result_df.apply(
lambda row: get_rewrite_suggestion(row["query"], row["headings"]), axis=1
)
#結局ここのプロンプト次第でより良いものが作れるはず。
# --- 9. 保存 ---
result_df.to_csv("gsc_similarity_headings_with_suggestions.csv", index=False, encoding="utf-8-sig")
print("✅ gsc_similarity_headings_with_suggestions.csv に出力しました。")
回すと、サーチコンソール連携アカウントの選択が求められます。
選んで、その中で確認したいURLを打ち込みましょう。
その上で、OpenAIのAPIキーを打ち込めばcsvで処理してくれます。
まとめ
この記事で振り返っているうちに、作り込めばもう少し面白いものになりそうだな〜と思いました。
そしてひどく雑な記事だなとも…w
あくまでも備忘録程度なので、こんなクオリティで申し訳ないです。
このテーマについては近いうちリベンジします。
AIの修正内容に「ユニークに」とか「このテーマを調べるユーザーが起因しそうな内容をたくさん挙げて、端的にコンテンツに落とし込んで」とかも良さそうですね。
