
ahrefsのデータ整理簡易化のPythonコードになります。
ローカルでPythonを回せる方向けに生ファイルと、そうでない方向けに「Google Colab」側の公開もしておきました。
このSEO新時代に、keyword的なトピックなんか需要なさそうなんですが、備忘録として掲載させてください。
ちなみに、アイデアとしては下記ブログ様を参考にしております。
【Python×SEO】AhrefsのデータからURLごとのトラフィック上位5キーワードを抽出する
悠生/Python×SEO様の記事をTwitterで見かけて、SEOとPython面白いなと色々やってみるようになりました。ありがとうございます。
▼今回の完成品はこちら
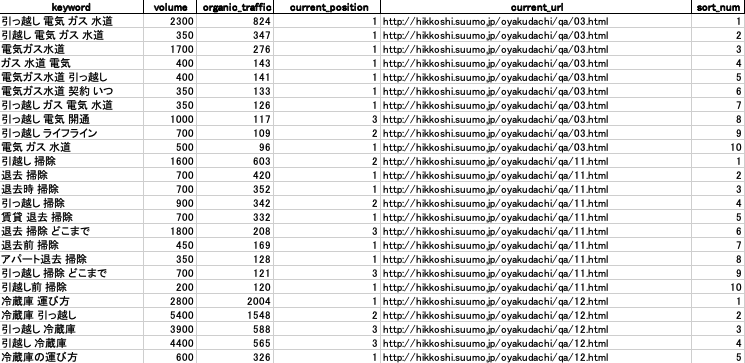
(データ引用・出典:https://suumo.jp/ 様)
ahrefsにおける、organic keywordをcsvで落とした際のデータです。
URL別に、想定トラフィック順にTOP10つづ、ソートさせています。
正直、死ぬほどニッチな内容ですが、そのニッチな誰かが使ってくれたり、手掛かりになればと思ってます。
トラフィックを軸に置いているので、自ずと高順位・ボリューム多のものが多いです。
また、ahrefsのプランに応じて、KWを拾いきれる限度があるので、URLによって10個も取れていないケースもあります。
そもそも、ahrefs側でデータを見ているケースもあると思いますが、今回はcsvに落とした後の部分です。
▼特に何もソート等せずにorganic keywordを落とした際のデータ。
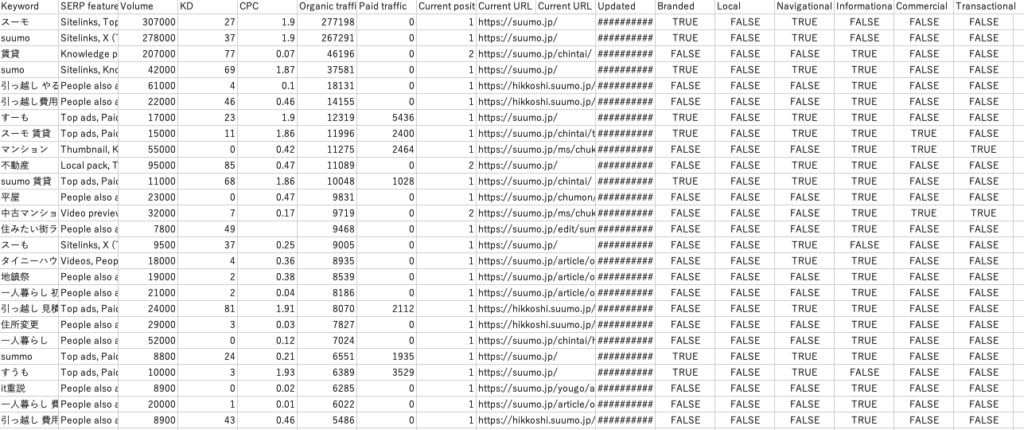
(データ引用・出典:https://suumo.jp/ 様)
地味に見づらい。
SEO担当者なんてデータ整理が仕事なんで、落としたデータのフィルタリングや整理自体、自分でできるとは思うのですが、勝手にソートさせて、その間に頭使うなり他の作業できる方が効率良いですよね。
ahrefsで落とすデータ整理って結構色々なバリエーションある(私が普段面倒と感じることが多い)ので、小出しで使えそうな整理コードを紹介していければと思います。
てなわけで、どうぞ。
目次
大前提として必要なデータ
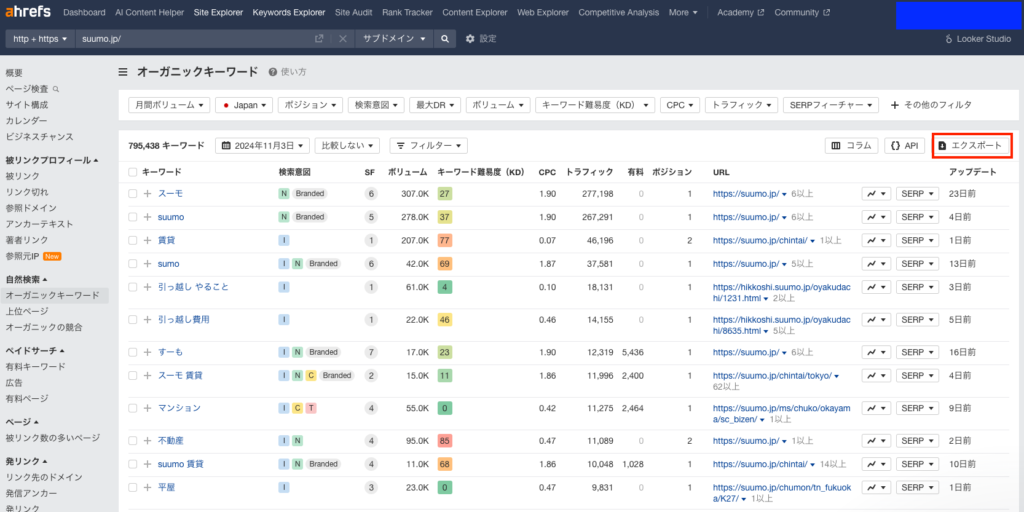
(データ引用・出典:https://suumo.jp/ 様)
今回使うデータの軸は、Site Explorerのオーガニックキーワードデータです。
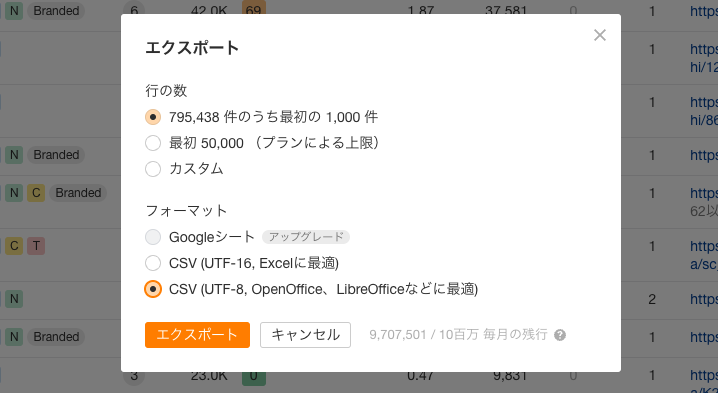
行の数は好きにしてください。
ただし、フォーマットは性質上、最下部「UTF-8」側にしてください。
ローカルでPython回せる方向け(コピペで実行のみ)
※基本的にフォルダをひとつ作ってそこに、Pythonファイルも土台となるcsvも入れて回しています。成果物も同じフォルダに生成されます。
import polars as pl
CSV_PATH = 'organic_keywords.csv'
df = pl.read_csv(CSV_PATH, truncate_ragged_lines=True)
KEYWORD_LENGTH = 10 # URLごとに抽出するキーワード数
if __name__ == "__main__":
df = pl.read_csv(CSV_PATH, truncate_ragged_lines=True)
df.columns = [column_name.replace(' ', '_').lower() for column_name in df.columns]
df = df.select(["keyword", "volume", "organic_traffic", "current_position", "current_url"])
df_sorted_by_traffic = df.sort("current_url", "organic_traffic", descending=[False, True])
# URLごとにランクを振る
df_with_rank = df_sorted_by_traffic.with_columns(
sort_num=pl.col("organic_traffic").rank(method="ordinal", descending=True).over("current_url")
)
df_filtered = df_with_rank.filter(pl.col("sort_num") <= KEYWORD_LENGTH)
pandas_df = df_filtered.to_pandas()
pandas_df.to_excel('organic_keywords_rank.xlsx', index=False, engine='openpyxl')
・読み込ませる(ソートさせる)ファイル名を「organic_keywords.csv」にしておいてください。
あとは、そのまま実行していただければPolarsがえらい速さでデータを整理してくれます。
ライブラリには
- Polars
- Pandas
- openpyxl
を使用しています。
汎用性の高いものだと思うので、「既に入ってるで」って可能性もありますが、一応記載しておきます。
ローカルでPython回せない方向け(Google Colab)
ローカルでPythonを回せない人は、Google Colabで回しちゃいましょう。
「Python環境くらい作れよ」って気持ちもわからなくもないんですが、Google Colabが結構便利なのと、楽して早くやりたことができるならぶっちゃけなんでも良いと思うので、好きなようにやってください。
▼Google Colabのリンクです。
csvの読み込みに少し時間がかかるのが気になりますが、それ以外は簡単です。
開くと、上記のような感じになるので
になるので、「CSVファイルの読み込み」箇所左の再生マークをクリック。
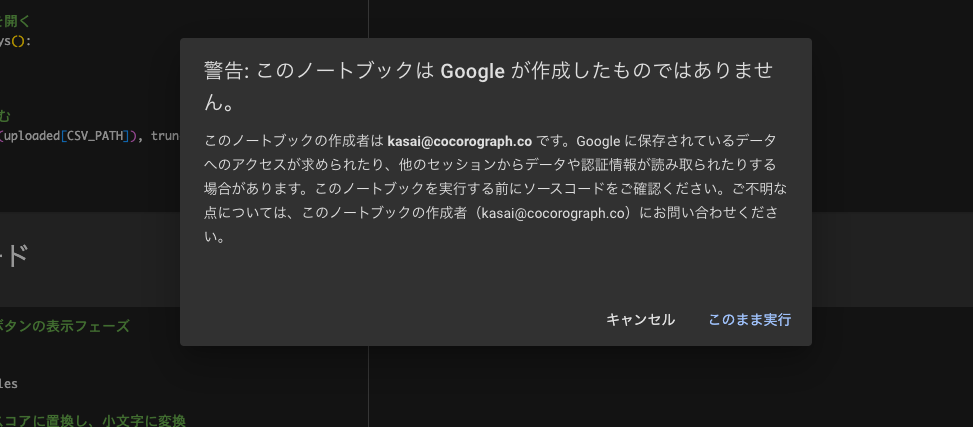
すると、こんな警告が出ます。
私のことを信じてくださる方は「このまま実行」をクリックしてください。
初めて使われる方は、バックグランドの準備的な感じに若干時間がかかるかもしれません。
あとは、CSVのアップロードボタンが表示されますので、ソートしたいcsvを入れて、「処理とダウンロード」箇所の再生マークをクリックしてください。
※こちらの場合、csvファイルのファイル名はなんでもOKです。
終わると勝手にダウンロードされます。
あとは煮るなり焼くなり、うまくデータを整理してください。
今後、エラーが起きたら&今後起こるかもの話
余談ですが、今後起こりそうなエラーの要因として、ツール側のアップデートがあります。
本コードで言えば、
df = df.select(["keyword", "volume", "organic_traffic", "current_position", "current_url"])上記のように、ダウンロードした既存列の名前を軸に内容の整理をしています。
もしエラーが生じて、AI等に聞いてみて「〜〜という値がない・参照できない」みたいなこといったら、参照しようとしている名前がアプデ等によって、変更されている場合があります。
具体例として、起こり得そうなのは、何か新しい指標が追加されて、「volume」が「keyword_Volume」になったなど。
もちろん、ツールを作っている側の目線としてそういった部分は一定の考慮をしていると思いますので、多くないと思います。
念の為の話でした。
おわりに 〜最近のSEOとキーワード選定〜
AI時代なんで、こんなんよりもっと良いものを作れますね。
自分も改良の余地があれば、随時更新してみます…。
そうそう。
最近、SEOでキーワードと睨めっこって減りましたよね。(そんなことない?w)
誤解のないようにいえば、綺麗事を抜きにした上でのSEO戦略として必要な要素ではあるんですけれど。
コラムやってないサイトが、「悩み解消」に向けた綺麗事コンテンツだけ書いても、売り上げは増えないんで、どうしても一定の露出やセッションを増やすためにキーワードを軸に動く場合や、シンプルに数字の増加をKPIやCVと求められるクライアントもいるでしょうし。
ただ、やはり現代のSEOにおいてキーワードベースでコンテンツ設計をするというよりは、ユーザーのニーズベースで必要なキーワードを洗うというか、そんな印象です。
このブログ書いてても思います。
意外にこんなクソみたいな自由な書き方していても、キーワード引っかかってたりするんです。
過去記事の、「監修者情報をコピペで入れたい」みたいな記事とかまさに。
競合を見ていると「EEATの話」や「監修者情報を載せた方が良い理由」とか、わからなくもないんですが、「監修者情報をコピペで入れたい!」ってテンションの人は「そんなことどうでも良い」or「それがわかってるから、楽に実装したい」みたいな温度感ですよね。作った自分は少なくともそうでした。
あと大事なのは、「自分はこうやってるよ・こんなこと悩んだよ」みたいな内容。
では。
