
目次
はじめに
※このサイトではChatGPTや、CursorによるAI補助によるコーディングを掲載しています。
ある程度言語を活用し、理解しておりますが、あくまでも専業のコーダーが掲載しているわけでありません。必ずしも正しい文法や記述方法ではない可能性がありますので、ご了承ください。
一般良識の範囲として記載内容に問題がある場合は、お伝えいただけますと幸いです。
あくまでも、マーケターやコンサルが、AI(文名の利器)を活用して普段の業務を少し楽に・幅を広げるためのtipsを意識しています。
【Python×SEOシリーズ】は少しSEOを意識したタイトルです。
最近(2024年1月現在)において、こんな小さなサイトでもある程度芯を食っていれば上がっている印象ですので、実験です。
「誰かの痒いところに手がとどく・助け」にはなりたいのですが、Googleの方へ変に向きたくはないので、妙なSEOっ気は極力出さないように注意します。
▼今回の成果物はこちらです。
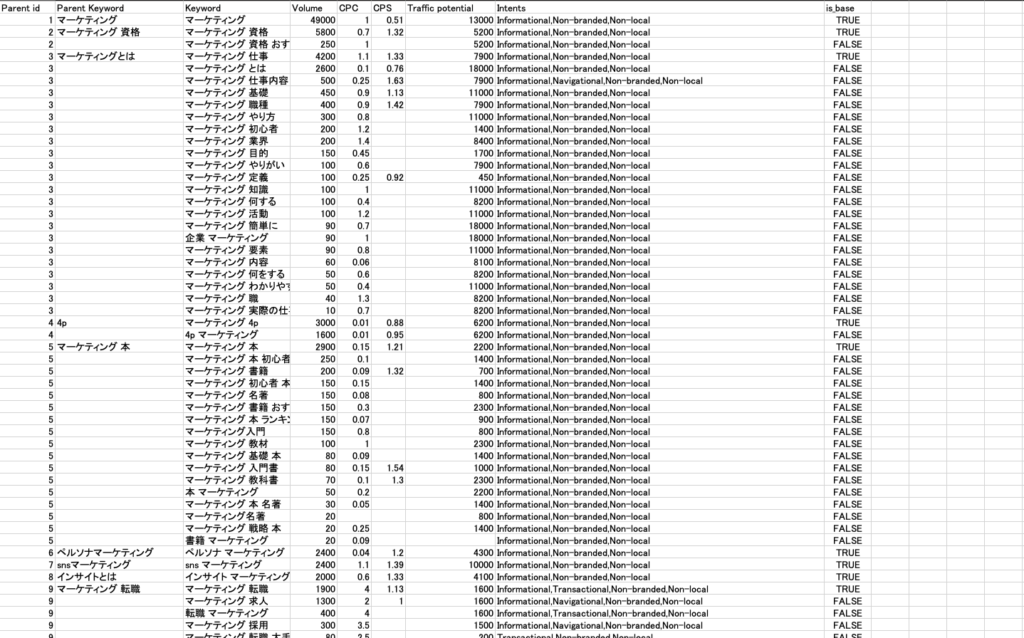
もともと、ahrefsのコラムにて紹介されていた、海外SEOプレイヤーが作ったキーワードを親テーマ別にネストさせて、目的(トランザクショナルクエリとかの分類)別で表示させるみたいなシート(上記画像みたいなやつ)がめちゃくちゃ良かったんです。
簡単に伝えるのであれば、
読み物向けコラムをつくるための、親テーマ軸にネストしたキーワードリスト
って感じです。
そもそも、親テーマいるか?みたいな意見も分かるんですが、ちょっと成果物としてリッチなのと、クラスター的なイメージがざっくりでも視覚的にあるので良いかなと。
元データあるなら自作じゃなくても良くないか
なぜ自作で作ったのかといますと、
- 元ファイルの設定が結構膨大で大変だった
- 最近ahrefsにて、クエリ別の情報が実装された
- 自分の欲しい情報に精査したかった
一応順に解説しておきます。
元ファイルの設定が大変
元データは、Pythonの学習機能使って、クエリの分類基準をめちゃくちゃ細かく設定してありました。ただそれが英語で書かれているので、日本語クエリに適用するためには中身の精査の箇所を「英語to日本語」にする必要があり少し重たかったです。
英語ペラペラで海外SEOできれば、もっと仕事の楽さを感じることができたり、先人のノウハウが楽に使えるな…と。
最近ahrefsにて、クエリ別の情報が実装された
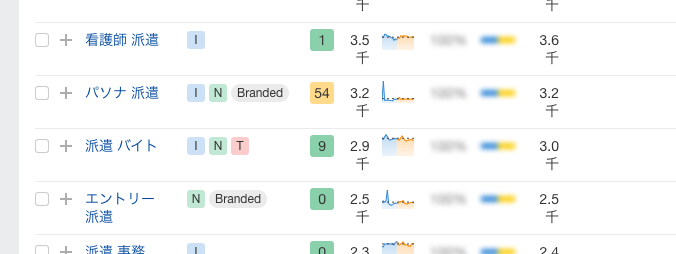
キーワードの右側に、「I」とか「N」とか「Branded」とかラムネみたいなアイコンがついています。
csvに落としても乗っかっているので、ここをフラグにすることができたので、ざっくりな分類分けとしてはひとまずOKかなと思いました。
実装された後、マーケアカウントみたいなのが、「もういいだろう!」ってくらい、数日もこの呟きばっかりで鬱陶しかったです。
自分の欲しい情報に精査したかった
不本意な発言と言いますか表現なんですが、「SEO側へ注力するための記事作成向けKWリスト」という前提で使えるツールにしたかったんです。
前回の記事の終わりにお話ししたのですが、現代のSEOにおいて、キーワードから念入りに設計するケースが減ったというか、ユーザーのニーズからKW設計をすべきと…。
クエリタイプを絞れば、横展は色々できると思うのですが。
SEO屋さんやってれば、クライアントの意向に沿う必要が生じます。
ただ、そこにエネルギーと時間を使うのは本質的ではないので、記事コンテンツつくらないきゃいけないSEO屋さんなどに使って欲しいKWリストって感じです。
そのため、ahrefsの分類分けは「Informational」のクエリに絞ってます。
大前提として必要なデータ
今回は、
- サイト軸を「Acsv」
- キーワード軸を「B.csv」、「C.csv」
としました。
キーワード群に関しては、「サジェスト」と、「よくある質問」のみにしました。
パターンとしてはいくらでも出せるんですが、今回のSEO向けの施策って本質ではないと思っているんです。
なので、「露出を軸に狙った記事作成の中でもユーザーの興味を狙いたい」という意向のもと、質問やサジェストのキーワード群をチョイスしました。
サイト軸「A.csv」(サイト編)
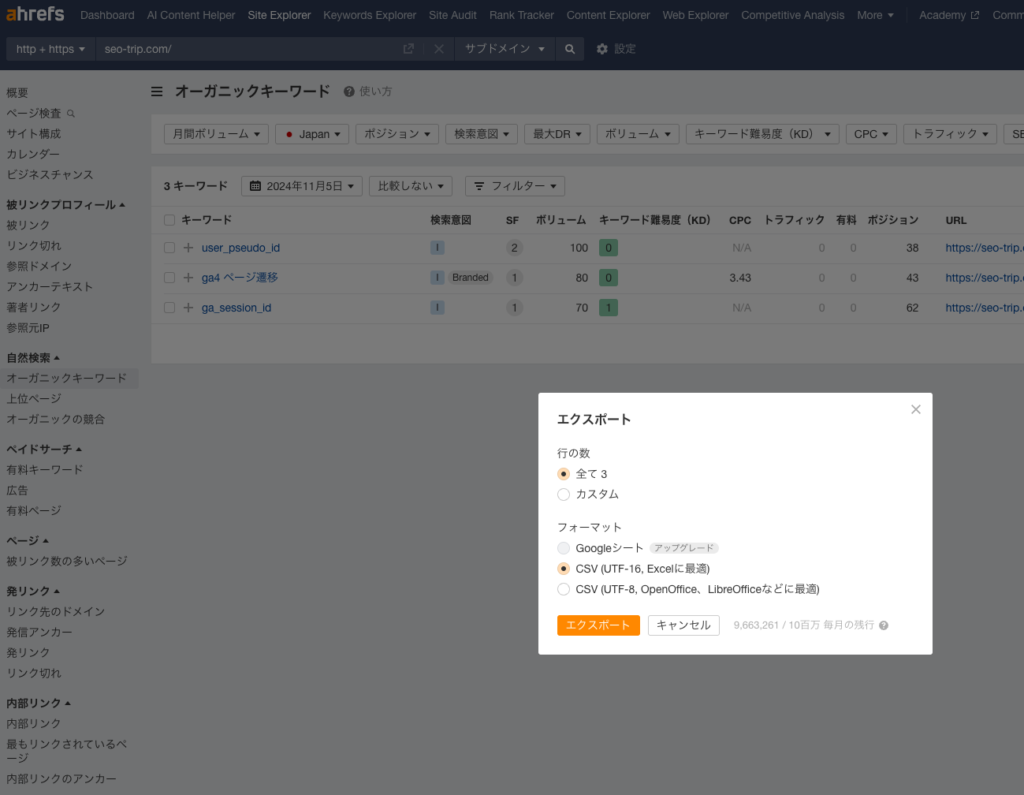
このサイトドメインにしてます。
メディア動かし始めたばっかりなので、クソみたいなデータ。
Site Explorer>オーガニックキーワード
と進みます。
前回はエンコード・デコードの処理が面倒だと思ったのですが、今回は、そのままutf-16でいきましょう。(すみません、コーダーじゃないんでその辺ガバガバです。)
落としたデータを「A.csv」と名付けておいてください。
キーワード軸「B.csv」(サジェスト編)
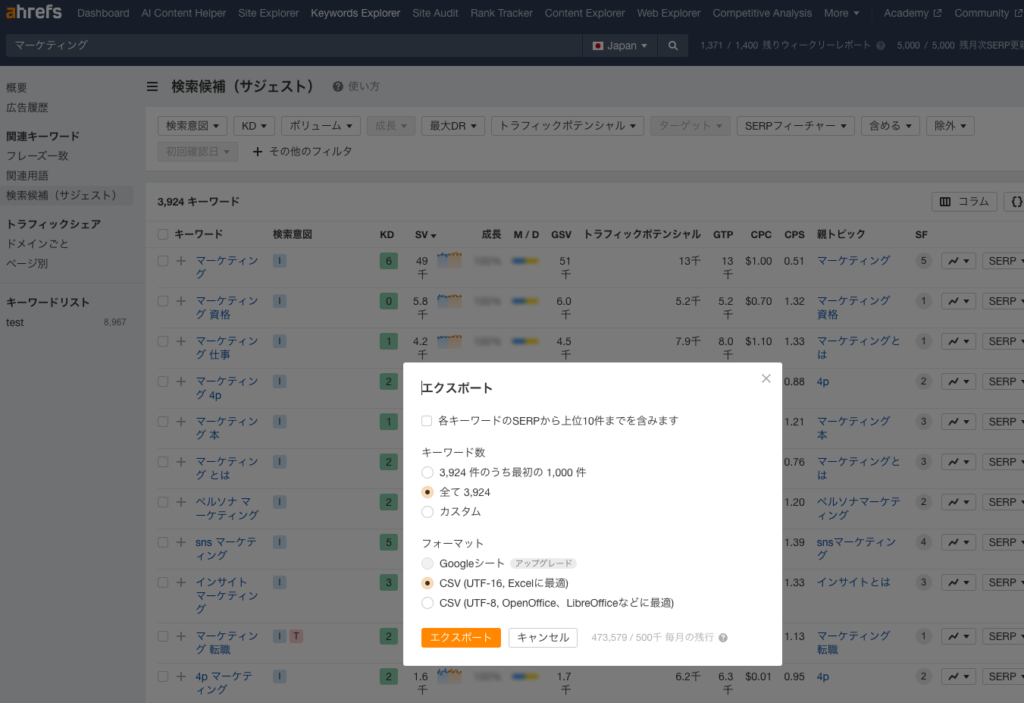
トピックを出せるキーワード群を今回は2つ使います。
まずはサジェスト群です。
Keywords Explorer>左側サイドバーより関連キーワード>検索候補(サジェスト)
と進みます。
落としたデータを「B.csv」と名付けておいてください。
キーワード軸「C.csv」(関連する質問編)
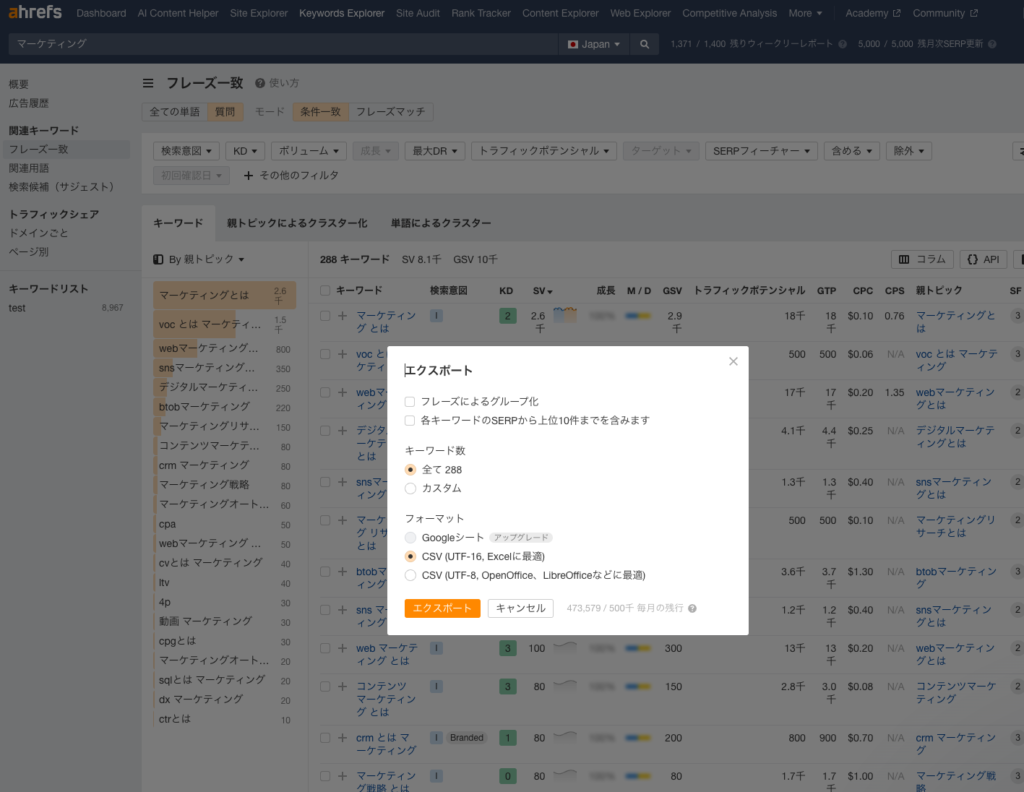
こちらは、
Keywords Explorer>左側サイドバーより関連キーワード>フレーズ一致(質問)
にしました。(多分これ関連する質問だよね?)
こちらも、落としたデータを「C.csv」と名付けておいてください。
これで前提準備はOKです。
ローカルでPython回せる方向け(コピペで実行のみ)
※基本的にフォルダをひとつ作ってそこに、Pythonファイルも土台となるcsvも入れて回しています。成果物も同じフォルダに生成されます。
下記コードです。
import pandas as pd
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl.styles import Font, Alignment
# 1. CSVファイルを読み込む(encodingエラーに対処)
df_a = pd.read_csv('A.csv', encoding='utf-16', delimiter='\t', on_bad_lines='skip')
df_b = pd.read_csv('B.csv', encoding='utf-16', delimiter='\t', on_bad_lines='skip')
df_c = pd.read_csv('C.csv', encoding='utf-16', delimiter='\t', on_bad_lines='skip')
# 重複削除処理を関数化
def remove_duplicates(df_base, df_compare, key_column='Keyword'):
# 重複する行を削除(特定の列をキーに重複を判断)
columns_to_keep = ['Keyword', 'Volume', 'CPC', 'CPS', 'Parent Keyword', 'Traffic potential', 'Intents']
existing_columns = [col for col in columns_to_keep if col in df_base.columns]
merged_df = df_base[existing_columns][~df_base[key_column].isin(df_compare[key_column])]
# 必要な列だけを残す
filtered_df = merged_df[existing_columns]
# 特定の列の文言でフィルタリングして、特定のキーワードを含むものだけ残すが「Branded」および「Local」は除外
target_column = 'Intents'
if target_column in filtered_df.columns:
keywords_to_keep = ['Informational', 'Non-branded', 'Non-local']
final_df = filtered_df[filtered_df[target_column].str.contains('|'.join(keywords_to_keep), na=False) & ~filtered_df[target_column].str.contains('Branded|Local', na=False)]
else:
final_df = filtered_df
# 列の順番を変更して「Parent Keyword」を「Keyword」の左側に配置
columns_order = [col for col in ['Parent Keyword', 'Keyword', 'Volume', 'CPC', 'CPS', 'Traffic potential', 'Intents'] if col in final_df.columns]
final_df = final_df[columns_order]
return final_df
# Bを土台にしてAを整理
df_sajest = remove_duplicates(df_b, df_a)
# Cを土台にしてAを整理
df_question = remove_duplicates(df_c, df_a)
# ネスト処理を関数化
def create_nested_dataframe(final_df):
nested_dict = {}
no_parent_rows = []
parent_id_counter = 1
for _, row in final_df.iterrows():
parent_keyword = row.get('Parent Keyword', '')
if pd.isna(parent_keyword) or parent_keyword == '':
row['Parent Keyword'] = 'no-parent'
row['Parent id'] = 'no-parent'
row['is_base'] = False
no_parent_rows.append(row)
else:
if parent_keyword not in nested_dict:
nested_dict[parent_keyword] = {
'parent_id': parent_id_counter,
'children': []
}
parent_id_counter += 1
row['Parent id'] = nested_dict[parent_keyword]['parent_id']
row['is_base'] = True if len(nested_dict[parent_keyword]['children']) == 0 else False
nested_dict[parent_keyword]['children'].append(row.to_dict())
nested_output = []
for parent, data in nested_dict.items():
parent_id = data['parent_id']
children = data['children']
for i, child in enumerate(children):
if i == 0:
child['Parent Keyword'] = parent
child['is_base'] = True
else:
child['Parent Keyword'] = ''
child['is_base'] = False
child['Parent id'] = parent_id
nested_output.append(child)
for row in no_parent_rows:
nested_output.append(row.to_dict())
nested_df = pd.DataFrame(nested_output)
columns_order = [col for col in ['Parent id', 'Parent Keyword', 'Keyword', 'Volume', 'CPC', 'CPS', 'Traffic potential', 'Intents', 'is_base'] if col in nested_df.columns]
nested_df = nested_df[columns_order]
nested_df.sort_values(by=['Parent id', 'is_base'], ascending=[True, False], inplace=True)
return nested_df
# ネスト化データフレームの作成
df_sajest_nested = create_nested_dataframe(df_sajest)
df_question_nested = create_nested_dataframe(df_question)
# 9. 結果を新しいExcelファイルに保存し、フォーマットを整える
wb = Workbook()
# サジェストシート
ws_sajest = wb.active
ws_sajest.title = "サジェスト"
for r_idx, row in enumerate(dataframe_to_rows(df_sajest_nested, index=False, header=True), 1):
ws_sajest.append(row)
if r_idx == 1:
for cell in ws_sajest[r_idx]:
cell.font = Font(bold=True)
# 質問シート
ws_question = wb.create_sheet(title="質問")
for r_idx, row in enumerate(dataframe_to_rows(df_question_nested, index=False, header=True), 1):
ws_question.append(row)
if r_idx == 1:
for cell in ws_question[r_idx]:
cell.font = Font(bold=True)
# 列幅の調整とフォントサイズの設定
for ws in [ws_sajest, ws_question]:
for col in ws.columns:
max_length = 0
for cell in col:
try:
max_length = max(max_length, len(str(cell.value)))
except:
pass
adjusted_width = (max_length + 4)
ws.column_dimensions[col[0].column_letter].width = adjusted_width
for cell in col:
cell.font = Font(size=14)
cell.alignment = Alignment(vertical='center')
# Excelファイルを保存
wb.save('output.xlsx')
print("処理が完了しました。結果は output.xlsx に保存されています。")
普段使用していますので、エラーを吐く想定はありませんが、エラーを吐いたらChatGPTとかに聞いてみてください。
全てのcsvと同じフォルダで回していただければ冒頭でお伝えした、成果物ができるはずです。
ローカルでPython回せない方向け(Google Colab)
ではローカルで実行できない方は下記のGoogle Colabから実行ください。
https://colab.research.google.com/drive/166Nz3y4yqbIyoVSSKfAaBrikEEeKwikG?usp=sharing
まずはCSVを読み込ませる
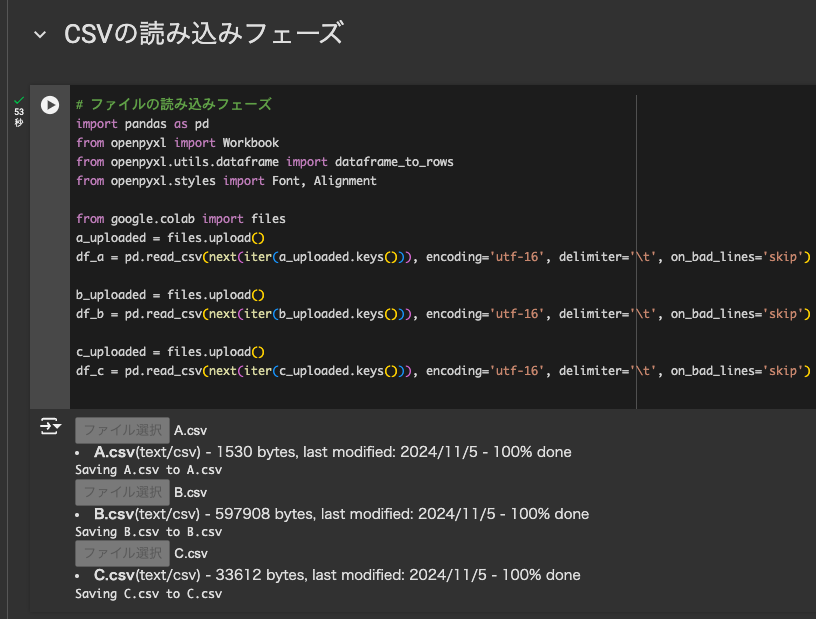
まず、「CSVの読み込みフェーズ」の再生マークをクリックしてください。
ここでは、先ほどのCSVを、AからB、Cと順番に読み込ませてください。
上記画像のように再生マークの左に緑色のチェックマークが表示されればOKです。
そして実行フェーズ
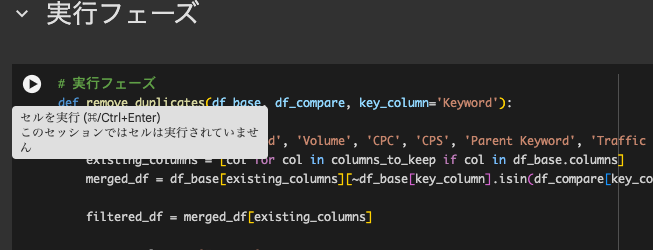
そしたら実行フェーズの再生マークをクリックしましょう。
処理が終われば勝手にダウンロードされます。
※KW数の量によって時間が多少かかるかもしれません。
アウトプット内容の列について
多分、何ヶ所か、「何この列?」みたいなもの入っていると思います。
Parent id
これは、親テーマとネストにする際にフィルター等でぐちゃぐちゃになった際の目印です。
Intents
これは、ahrefsのクエリ分別です。
今回は記事コンテンツ向けのKW羅列なので一応、
- Non-branded:指名ワードではない
- Non-local:ローカルクエリ含んでいない(これは一応です。)
- Informational:読み物向けクエリである
といった指定を入れております。
ただ、ahrefsの日本語認識が甘いのか、どうしても指名ワードや地域クエリが含まれてしまうケースがあります。(Non-brandedになっているのに)
なので、一応、種別が誤っていないか確認できるように残しております。
is_base
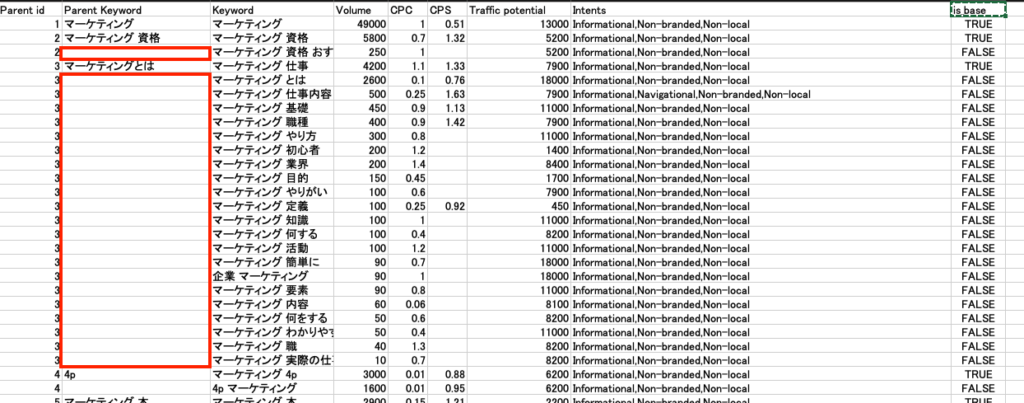
これ、擬似ネストを作るために同じ親テーマの子キーワードには、空白を当てています。(画像参照)
セルを結合しちゃっても良いんですが、結合すると、その後の処理や加工に影響を与えかねないので、あえて空白にしています。
ただ、1つ目の「Parent id」だけではフィルターをかけた際にこの空白の親子関係が崩れてしまいます。
ですので、「最初に軸となる親が来て、以降のネスト要素が空白になる」が壊れないために、このidを振っています。
そうすることで、最終的に「Parent id」を昇順にフィルターをかければ、最初の状態に綺麗なネスト感を出しつつ戻すことができるのです。
成果物の使い方
「自社が持っていないかつ、一般ユーザーが気にしている」みたいな簡易KWクラスターなんで、必要なものがぱっと見でわかるのは良いかなと。
また、そこに応じて、「どこから攻めるか」など…色々勝手は良いデータじゃないかなぁと思ってます。
テーマが近いものが集約されているので、「親テーマを狙うために子KW全てをコンテンツ化せねばいけない」ことはないと思っています。意図は同じなので、検索結果もほとんど同じじゃないかなと。
使い方具体例
例えば、下記例で具体例を挙げてみます。(あくまで私の浅い感覚ですが)

私であれば、「マーケティングとは」の記事を作る上で、必要な内容というテンションで構成作成等に使います。
丁寧なクラスター設計をするのであれば、上記全てを軽く触れる程度の親記事を作って、それぞれ内部リンクで、各種詳細を記載している記事を作って繋げます。
ただし、「わかりやすく」と「簡単に」は同じだと思うので1つにしますし、「仕事」と「仕事内容」も近年の傾向で言えば同じで良いんじゃないかなあと。
ある程度整理しつつ、必要なコンテンツ設計には便利だなと感じています。
おわりに〜AIの精度が高い近年〜
最後までご覧いただきありがとうございます。
もともとは、自分の作業簡略化のために始めた小さなナレッジがたくさんあるので、なにか使えないか?と記事としてアウトプットし始めています。
ですので、このAI時代の少し前から同じ成果物を出せる仕組みを作っていました。
記事にするにあたって、同じアウトプットを求めてコードも書き直していますが、最近は本当に早くて欲しい答えがすぐに来ます。
調べながらPythonを動かしていた当時に比べて、やりたいことを形にするまでがめちゃくちゃ早いです。
良い時代ですし、同時にハードルの高い面倒な時代だなとも感じますw
(多分この記事を読んだ専業コーダーさんとかは色々文句あると思いますし)
ただ、だからこそ、カジュアルに使えるものを使った時短tipsを堂々と発信してみたいと思いました。
発信するまでもない自分の時短術を公開して、あわよくばいつか色々な人のフィードバックや反応がもらえたら楽しいなとも思います。
ありがとうございました。
